

Contracts contain valuable data, and modern models can be trained to automatically recognize and interpret this information. This is made possible by Natural Language Processing, a field of artificial intelligence that analyzes text and extracts relevant insights.
In this article, we help you understand Natural Language Processing (NLP).
Natural Language Processing: Definition
Natural Language Processing (NLP) is a field of Artificial Intelligence (AI) with numerous applications: from machine translation tools capable of understanding and translating our texts into over a hundred languages, to personal assistants that—together with Speech Processing technologies—help simplify scheduling appointments and organizing our calendars.
NLP is one of those fields that continuously transforms our daily lives.
What exactly does NLP entail?
Simply put, Natural Language Processing focuses on the various ways to analyze a text and extract relevant information, which serves as the foundation for creating systems capable of solving a wide range of tasks, from simple to complex.
These tasks include :
- entity recognition (e.g. automatic detection of names, dates, amounts, etc.) ;
- question-answering (e.g. question about an event appearing in the document) ;
- or text classification (e.g. automatic categorization of an e-mail as spam/non-spam)..
The application of NLP in the legal field
The use of NLP on a single task is often of limited interest, except in academic circles where the focus is on the operating mechanisms of these methods.
In practice, more concrete NLP applications make the most of these technologies by building more complex systems, or pipelines, which break down the problem into a succession of simple tasks. Each of these tasks is then addressed using Machine Learning (ML) methods, along with rules to ensure consistency.
At DiliTrust, we offer a simplified Contract Lifecycle Management (CLM) solution that includes :
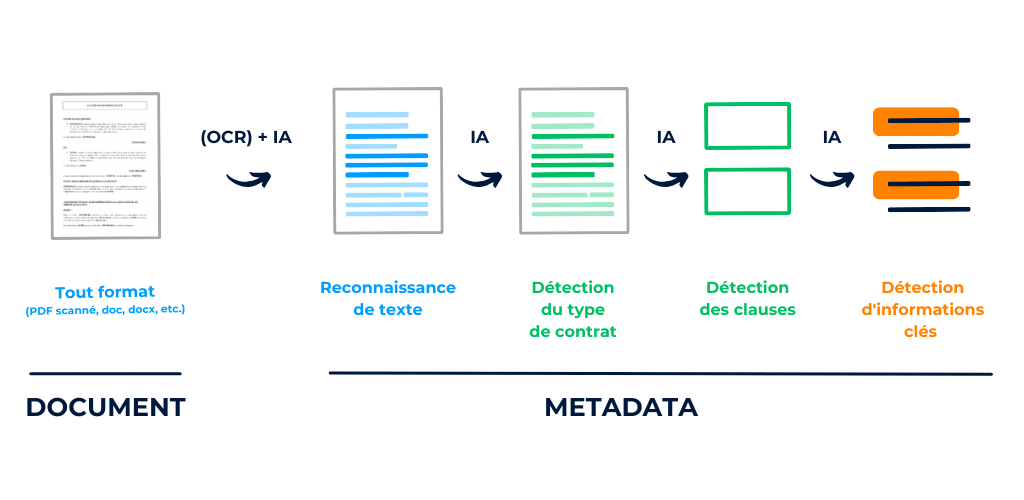
Illustration of the Key Steps in the Contract Analysis Pipeline
Two Key Steps in NLP: Representation and Decision
Despite the wide variety of tasks involved in NLP, there are essentially two key concepts that are almost always present.
The first is representation (also known as vectorization, embedding, etc.).
Indeed, in its raw form, text is unintelligible to a machine and therefore requires a transformation to obtain numerical values that can be used for various statistical computations.
Given these representations, the next step involves performing calculations and making a decision, which can take various forms such as classification, information extraction, etc.
To become familiar with these two concepts, we will study a concrete case of text classification, which will allow us to see how to build a system capable of transforming texts and categorizing them into different classes of interest.
IMDb Movie Reviews
To get a grasp of the various NLP methods, we begin here with a standard case of text classification. Specifically, we focus on the IMDb dataset, which contains 50,000 movie reviews posted on the site of the same name.
Our goal will be to automatically determine whether these reviews are positive or negative. This is a binary classification task since we are targeting exactly two categories.
In the following, we will use the Python programming language to build our sentiment analysis model.
Downloading the Data
First, we will retrieve the IMDb dataset using the datasets tool provided by Hugging Face:
Data Overview

Number of Documents per Category

The dataset consists of two parts: one for training the model and the other for testing.
Within each part, the reviews are evenly distributed across the target categories (0: negative, 1: positive).
Text Representation
To build our sentiment analysis model, we first need to transform our texts into representations that can be utilized by the various downstream decision-making algorithms.
Here, we opt for a standard transformation that effectively extracts useful information while filtering out less relevant data. This transformation is Term-Frequency Inverse Document-Frequency, or simply TF-IDF, which summarizes the content of a text based on the frequency of the different words appearing within it.
When applying TF-IDF to a set of texts, we start with the words that appear in these texts (also known as the vocabulary) and then count, for each text, the number of occurrences of each word within that specific text. This results in the Term-Frequency (TF), a vector containing the frequencies of the words appearing in each text.
The resulting vector might suffice; however, using raw frequencies has its drawbacks. Notably, the most frequent words (e.g., pronouns, auxiliaries, particles, etc.) are not necessarily the most useful. Therefore, we instead multiply the frequency of each word, for each text, by a value that decreases as the word appears in multiple documents. This forms the Inverse Document-Frequency (IDF) vector, calculated by taking the logarithm of the inverse of the frequencies across the different texts.
The following illustration outlines the protocol:
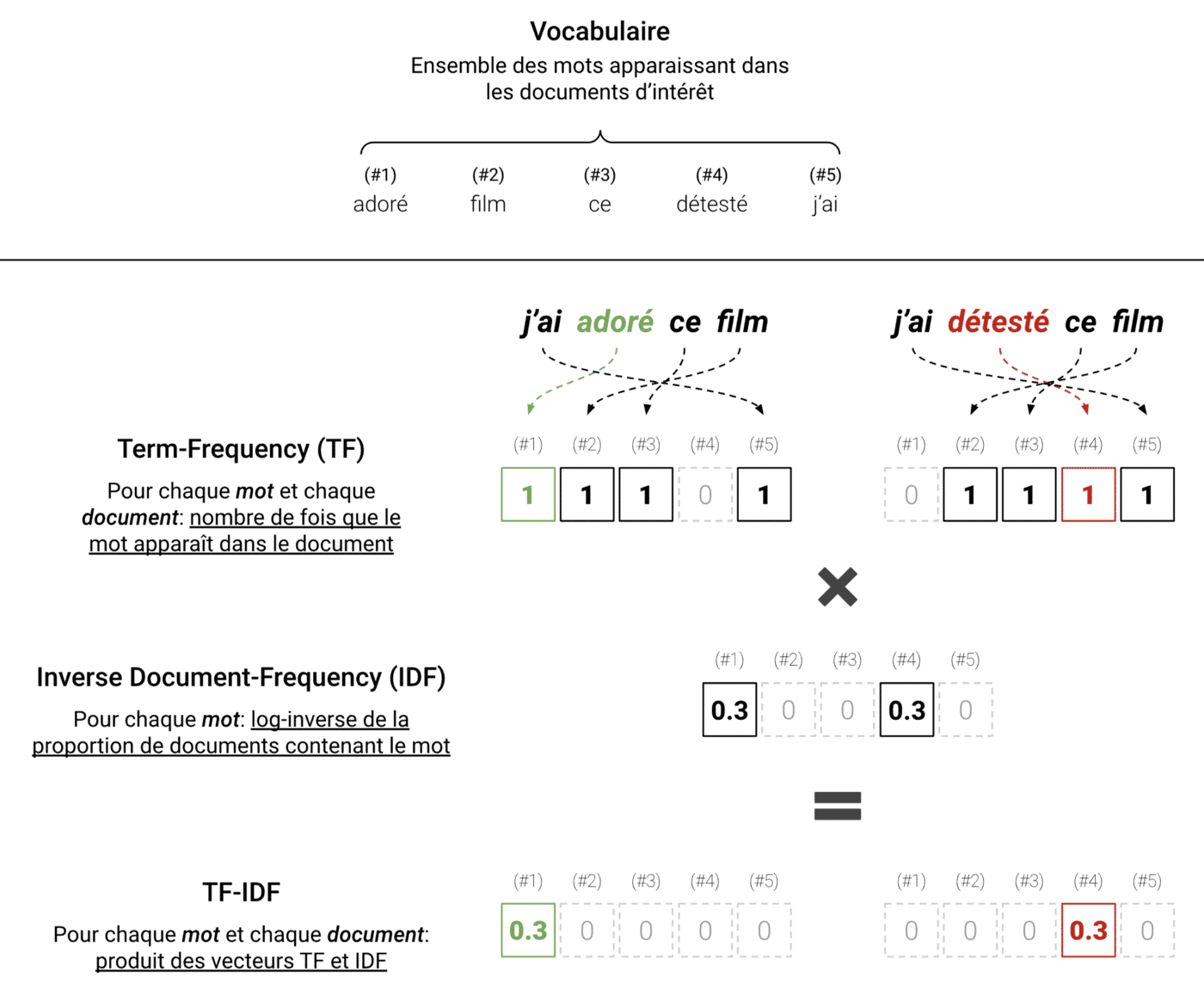
TF-IDF applied in a simple case with two sentences. Here, the important words are “loved” and “hated.” We see that TF-IDF represents the texts by filtering out noise and retaining relevant information.
In practice, applying TF-IDF to a real dataset is very simple. To do this, you just need to use the scikit-learn library, which offers various machine learning tools in Python.
Natural Language Processing is an interesting but vast topic. In this article, we familiarized ourselves with various aspects of NLP and introduced a standard case of text classification. However, there is still much more to explore.
In an upcoming article, we will explore the various parameters that can be adjusted to adapt the TF-IDF method to different needs. We will also see how to use these numerical representations to build a model capable of making decisions (i.e., automatically categorizing our IMDb reviews). Finally, we will introduce some more advanced concepts that will allow us to go further and understand the latest state-of-the-art developments in Natural Language Processing.


