

DiliTrust développe sa propre intelligence artificielle. Chaque jour, l’équipe d’apprentissage automatique (Machine Learning – ML) travaille sur cet outil innovant. Son principal domaine d’étude : les contrats. L’équipe entraîne des modèles capables d’identifier automatiquement les données présentes dans ces documents. Dans cet article, nous vous expliquons le Traitement Automatique des Langues (TAL). Ce domaine de l’intelligence artificielle analyse les textes pour en extraire des informations pertinentes.
Le traitement automatique des langues
Le Traitement Automatique des Langues (TAL) est un domaine de l’intelligence artificielle (IA) aux multiples applications. Il permet, par exemple, aux traducteurs automatiques de comprendre et traduire des textes en plus de cent langues. Il aide aussi les assistants personnels, qui, associés aux technologies de traitement de la parole, facilitent la gestion des rendez-vous et des calendriers.
Le TAL est en constante évolution et transforme notre quotidien.
En quoi consiste le TAL, plus exactement ?
En résumé, le Traitement Automatique des Langues (TAL) analyse les textes pour en extraire des informations utiles. Ces informations servent ensuite à développer des systèmes capables de réaliser diverses tâches, plus ou moins complexes.
Parmi ces tâches, on retrouve :
L’application du traitement automatique des langues dans le domaine juridique
L’utilisation du TAL pour une seule tâche a souvent un intérêt limité, sauf en milieu académique, où l’on étudie surtout ses mécanismes de fonctionnement.
En pratique, les applications concrètes du traitement automatique des langues exploitent pleinement ces technologies en construisant des systèmes plus complexes. Ces systèmes, appelés pipelines, divisent un problème en plusieurs tâches simples. Chaque tâche est ensuite traitée grâce à des méthodes d’apprentissage automatique (Machine Learning ou ML) et à des règles garantissant la cohérence globale.
Chez DiliTrust, nous proposons une solution de gestion simplifiée du cycle de vie contractuel (CLM, ou Contract Lifecycle Management), qui intègre notamment :
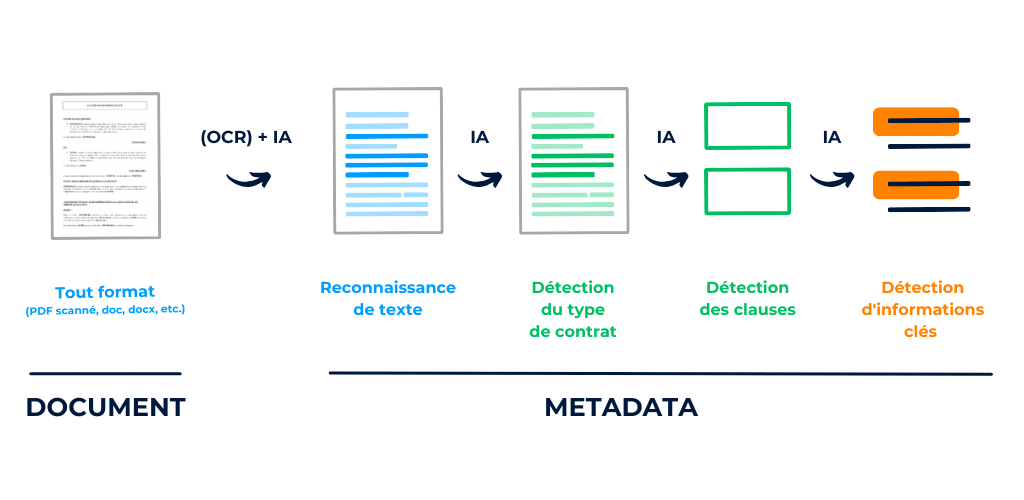
Illustration des étapes clés du pipeline d’analyse de contrats
Deux étapes clés en TAL : représentation et décision
Le traitement automatique des langues couvre une grande variété de tâches. Pourtant, deux concepts clés reviennent presque toujours.
Le premier est la représentation (aussi appelée vectorisation ou plongement).
Un texte brut est incompréhensible pour une machine. Il doit donc être transformé en valeurs numériques exploitables par des calculs statistiques.
Une fois cette transformation effectuée, l’étape suivante consiste à appliquer ces calculs pour prendre une décision. Cela peut se traduire par une classification, une extraction d’informations, etc.
Pour mieux comprendre ces deux concepts, nous allons étudier un cas concret de classification de texte. Cet exemple nous montrera comment construire un système capable de transformer un texte avant de le catégoriser en différentes classes d’intérêt.
Critiques cinématographiques IMDb
Pour explorer les méthodes du TAL, nous allons commencer par un cas classique de classification de texte.
Nous utiliserons le jeu de données IMDb, qui regroupe 50 000 critiques de films postées sur le site du même nom. L’objectif est de déterminer automatiquement si un avis est positif ou négatif. Il s’agit donc d’une classification binaire, car seules deux catégories sont possibles.
Dans la suite de cet article, nous utiliserons Python pour construire notre modèle d’analyse de sentiments.
Téléchargement des données
Tout d’abord, nous allons récupérer la base IMDb en exploitant l’outil datasets proposé par HuggingFace :
Aperçu des données

Nombre de documents par catégorie

Le jeu de données est divisé en deux parties : une pour l’entraînement du modèle et une pour le test.
Dans chaque partie, les commentaires sont répartis de manière équilibrée entre les deux catégories :
Représentation de textes
Pour construire notre modèle d’analyse de sentiments, nous devons d’abord transformer les textes en représentations exploitables par les algorithmes de prise de décision.
Nous utilisons ici une transformation standard mais efficace : le Term-Frequency Inverse Document-Frequency (TF-IDF). Cette méthode résume le contenu d’un texte en analysant la fréquence des mots tout en filtrant les informations moins pertinentes.
Comment fonctionne le TF-IDF ?
- Calcul du Term-Frequency (TF) :
- On recense tous les mots présents dans les textes (le vocabulaire).
- Pour chaque texte, on compte le nombre d’occurrences de chaque mot.
- On obtient ainsi un vecteur TF, qui indique la fréquence de chaque mot dans le texte.
- Ajout du Inverse Document-Frequency (IDF) :
- Les mots les plus fréquents (comme les pronoms ou auxiliaires) ne sont pas forcément les plus utiles.
- Pour éviter ce biais, on ajuste la fréquence de chaque mot en lui appliquant un facteur de pondération.
- Ce facteur, l’IDF, est calculé en prenant le logarithme de l’inverse de la fréquence du mot dans l’ensemble des textes.
L’illustration suivante schématise ce protocole :
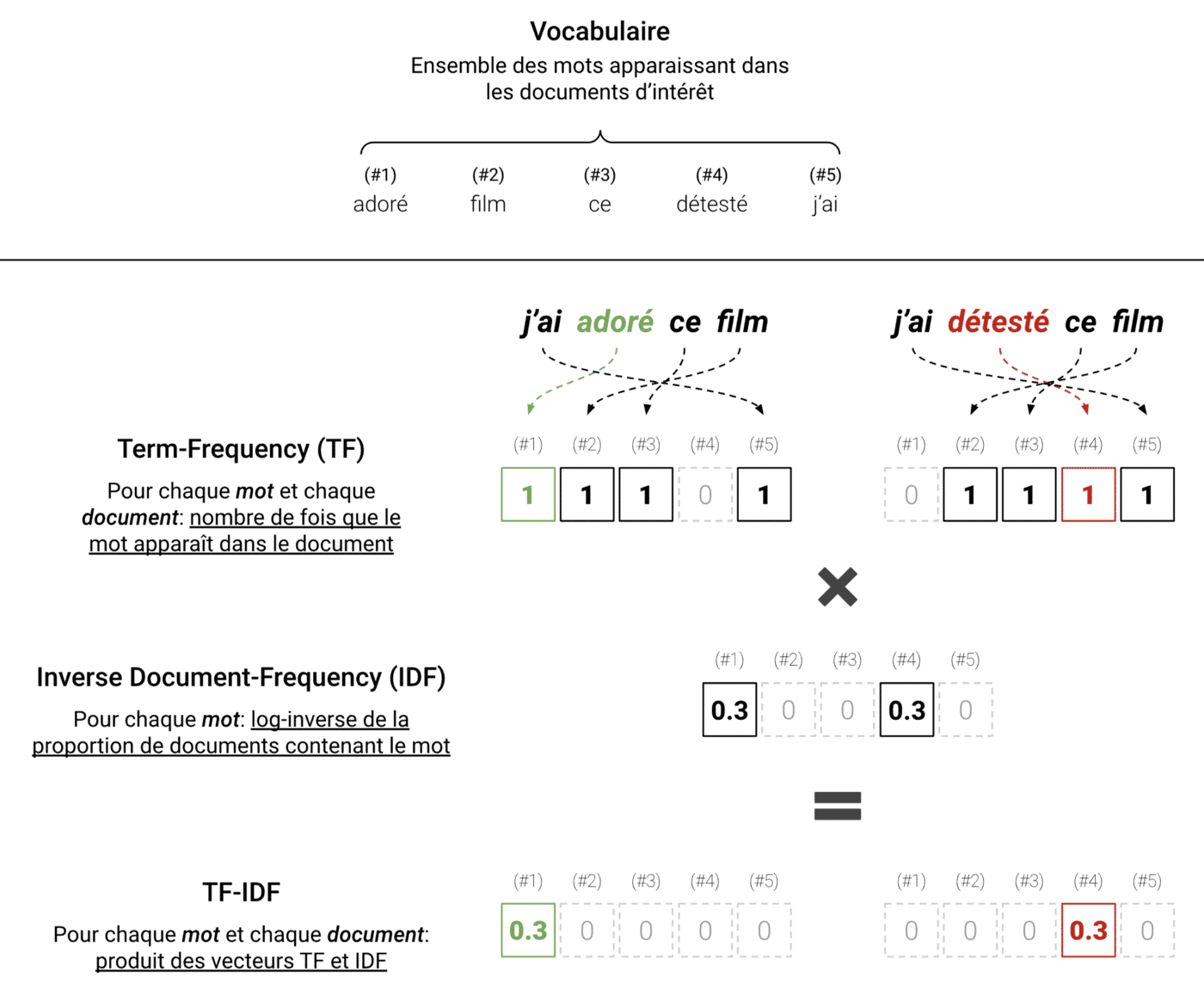
TF-IDF appliqué dans un cas simple à deux phrases. Ici, les mots importants sont “adoré” et “détesté”. On voit que le TF-IDF représente les textes en filtrant le bruit et en retenant l’information pertinente.
Appliquer un TF-IDF sur un jeu de données réel est très simple. La librairie scikit-learn, spécialisée en apprentissage automatique avec Python, propose des outils adaptés pour cela.
Le Traitement Automatique des Langues (TAL) est un domaine vaste et passionnant. Dans cet article, nous avons exploré ses principes de base et étudié un cas concret de classification de textes. Cependant, de nombreux sujets restent à approfondir.
Dans un prochain article, nous verrons :


