Die Verarbeitung natürlicher Sprache, auch Natural Language Processing, kurz NLP, ist ein Bereich der künstlichen Intelligenz, der die Analyse von Texten ermöglicht und sich mit der Interpretation der menschlichen Sprache beschäftigt. Zudem hilft er bei der Extraktion relevanter Informationen.
DiliTrust entwickelt seine eigene künstliche Intelligenz. Das Team für maschinelles Lernen (ML) verbringt seine Tage mit der Entwicklung dieses einzigartigen Tools. Die wichtigste Arbeitsressource für das ML-Team sind Verträge.
Dokumente wie Verträge enthalten wertvolle Daten, die von modernen Modellen automatisch erkannt und interpretiert werden können. Dies wird durch NLP erreicht. Diese Modelle werden darauf trainiert, die in diesen Dokumenten enthaltenen Daten automatisch zu erkennen.
Text- und Sprachdaten spielen dabei eine zentrale Rolle, denn es geht darum, Informationen aus juristischen Dokumenten zu extrahieren, zu analysieren und zu strukturieren, ein Prozess, der die Brücke zwischen menschlicher und maschineller Verarbeitung schlägt
In diesem Artikel helfen wir Ihnen, die natürliche Sprachverarbeitung (NLP) besser zu verstehen.
Natürliche Sprachverarbeitung (NLP)
Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) ist ein Bereich der künstlichen Intelligenz (AI) mit zahlreichen Anwendungen. NLP (z. B. durch Tokenisierung, Parsing, Embeddings) überführt menschliche Sprache in eine Form, die Maschinen verarbeiten können. Ein Beispiel sind maschinelle Übersetzungswerkzeuge, die unsere Texte verstehen und in über hundert Sprachen übersetzen können. Zudem gibt es persönliche Assistenten, die in Kombination mit Sprachverarbeitungstechnologien eingesetzt werden. Sie erleichtern die Terminplanung und unterstützen bei der Organisation unseres Kalenders.
NLP ist eines der Gebiete, die unser tägliches Leben ständig verändern. Insbesondere, wenn es um die Kommunikation zwischen Mensch und Maschine geht, gewinnen diese Technologien zunehmend an Bedeutung.
Was genau beinhaltet NLP?
Einfach ausgedrückt, konzentriert sich die natürliche Sprachverarbeitung auf die verschiedenen Möglichkeiten, einen Text und Sprache zu analysieren und relevante Informationen zu extrahieren, die als Grundlage für die Entwicklung von Systemen dienen, die in der Lage sind, eine breite Palette von Aufgaben zu lösen, von einfach bis komplex.
Zu diesen Aufgaben gehören:
- Erkennung von Entitäten, auch Named Entity Recognition (z. B. automatische Erkennung von Namen, Daten, Beträgen usw.);
- Beantwortung von Fragen (z. B. Fragen zu einem im Dokument vorkommenden Ereignis);
- oder Textklassifizierung (z. B. automatische Einstufung einer E-Mail als Spam/Nicht-Spam).
Diese Aufgaben sind Teil eines größeren Ziels: der Natural Language Understanding, also der Fähigkeit von Computern, die Bedeutung eines Textes zu erfassen.
Die Anwendung von NLP im juristischen Bereich
Die Anwendung von NLP auf eine einzelne Aufgabe ist oft nur von begrenztem Interesse, außer in akademischen Kreisen wie der Data Science, wo man sich mit den zugrunde liegenden Techniken beschäftigt.
In der Praxis machen sich konkretere NLP-Anwendungen diese Technologien zunutze, indem sie komplexere Systeme oder Pipelines aufbauen, die das Problem in eine Reihe einfacher Aufgaben zerlegen. Jede dieser Aufgaben wird dann mit Methoden des maschinellen Lernens (ML) bearbeitet, zusammen mithilfe von Regeln zur Gewährleistung der Konsistenz.
In der Praxis erstellen Unternehmen komplexe Verarbeitungspipelines. Diese bestehen oft aus mehreren Modulen, die jeweils auf bestimmte Teilaufgaben trainiert sind.
Ein Beispiel ist die Lösung von DiliTrust, die auf Deep Learning basiert und große Mengen juristischer Dokumente analysiert.
DiliTrust bietet eine vereinfachte Contract Lifecycle Management (CLM)-Lösung an, die Folgendes umfasst:
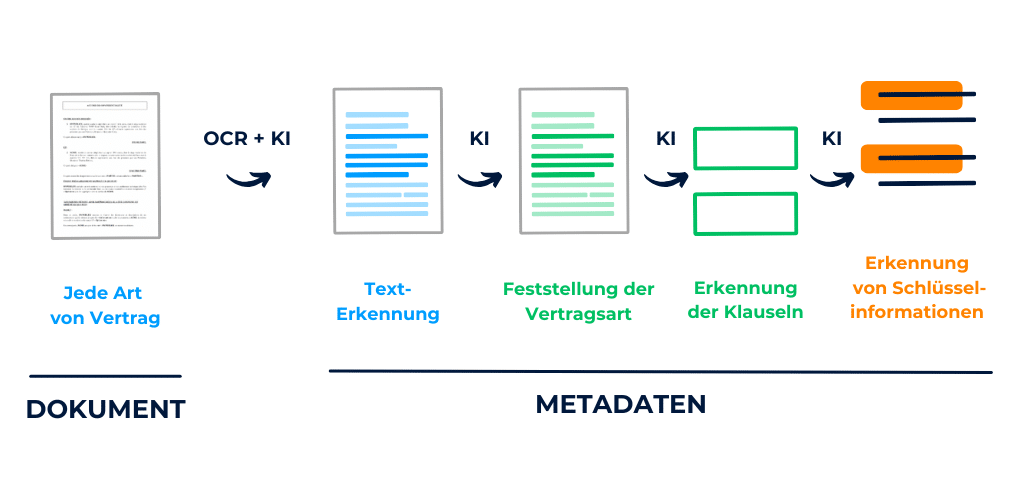
Illustration der wichtigsten Schritte in der Vertragsanalyse-Pipeline
Zwei Schlüsselschritte im NLP: Repräsentation und Entscheidung
Trotz der großen Vielfalt an Aufgaben, die mit NLP verbunden sind, gibt es im Wesentlichen zwei Schlüsselkonzepte, die fast immer vorhanden sind.
Ein Beispiel für einen modernen NLP-Ansatz ist Retrieval Augmented Generation, bei dem Modelle gezielt auf externe Informationen zugreifen, bevor sie eine Antwort generieren.
Das erste ist die Darstellung (auch bekannt als Vektorisierung, Einbettung usw.).
In seiner Rohform ist ein Text für eine Maschine unverständlich und muss daher transformiert werden, um numerische Werte zu erhalten, die für verschiedene statistische Berechnungen verwendet werden können.
Ausgehend von diesen Darstellungen werden im nächsten Schritt Berechnungen durchgeführt und eine Entscheidung getroffen, die verschiedene Formen annehmen kann, wie z. B. Klassifizierung, Informationsextraktion usw.
Um sich mit diesen beiden Konzepten vertraut zu machen, werden wir einen konkreten Fall von Textklassifizierung untersuchen, der es uns ermöglicht, ein System zu entwickeln, das in der Lage ist, Texte umzuwandeln und sie in verschiedene Klassen von Interesse zu kategorisieren.
IMDb Filmkritiken
Um einen Überblick über die verschiedenen NLP-Methoden zu erhalten, beginnen wir hier mit einem Standardfall der Textklassifizierung. Konkret konzentrieren wir uns auf den IMDb-Datensatz, der 50.000 Filmkritiken enthält, die auf der gleichnamigen Website veröffentlicht wurden.
Unser Ziel ist es, automatisch zu bestimmen, ob diese Bewertungen positiv, negativ negativ oder neutral sind, eine klassische Aufgabe der Natural Language Generation, die auf der Semantischen Analyse des Textinhalts basiert. Dies ist eine binäre Klassifizierungsaufgabe, da wir uns auf genau zwei Kategorien konzentrieren.
Im Folgenden werden wir die Programmiersprache Python verwenden, um unser Stimmungsanalyse-Modell zu erstellen.
Herunterladen der Daten
Zunächst werden wir den IMDb-Datensatz mit dem von Hugging Face bereitgestellten Dataset-Tool abrufen:
Überblick über die Daten

Anzahl der Dokumente pro Kategorie

Der Datensatz besteht aus zwei Teilen: einem zum Trainieren des Modells und einem zum Testen.
Innerhalb jedes Teils sind die Bewertungen gleichmäßig auf die Zielkategorien verteilt (0: negativ, 1: positiv).
Textdarstellung
Um unser Stimmungsanalysemodell zu erstellen, müssen wir unsere Texte zunächst in Darstellungen umwandeln, die von den verschiedenen nachgeschalteten Entscheidungsalgorithmen verwendet werden können.
Hier entscheiden wir uns für eine Standardtransformation, die nützliche Informationen effektiv extrahiert und weniger relevante Daten herausfiltert. Diese Transformation ist die Term-Frequency Inverse Document-Frequency, oder einfach TF-IDF, die den Inhalt eines Textes auf der Grundlage der Häufigkeit der verschiedenen darin vorkommenden Wörter zusammenfasst.
Bei der Anwendung von TF-IDF auf eine Reihe von Texten beginnen wir mit den Wörtern, die in diesen Texten vorkommen (auch als Vokabular bezeichnet), und zählen dann für jeden Text die Anzahl der Vorkommen jedes Wortes in diesem spezifischen Text. Das Ergebnis ist die Term-Frequency (TF), ein Vektor, der die Häufigkeit der in jedem Text vorkommenden Wörter enthält.
Der sich daraus ergebende Vektor könnte ausreichen; die Verwendung roher Häufigkeiten hat jedoch ihre Nachteile. Insbesondere sind die häufigsten Wörter (z. B. Pronomen, Hilfswörter, Partikel usw.) nicht unbedingt die nützlichsten. Daher multiplizieren wir stattdessen die Häufigkeit jedes Wortes für jeden Text mit einem Wert, der abnimmt, wenn das Wort in mehreren Dokumenten vorkommt. Daraus ergibt sich der Vektor der inversen Dokumenthäufigkeit (IDF), der durch Bilden des Logarithmus der inversen Häufigkeit in den verschiedenen Texten berechnet wird.
Die folgende Abbildung skizziert das Protokoll:
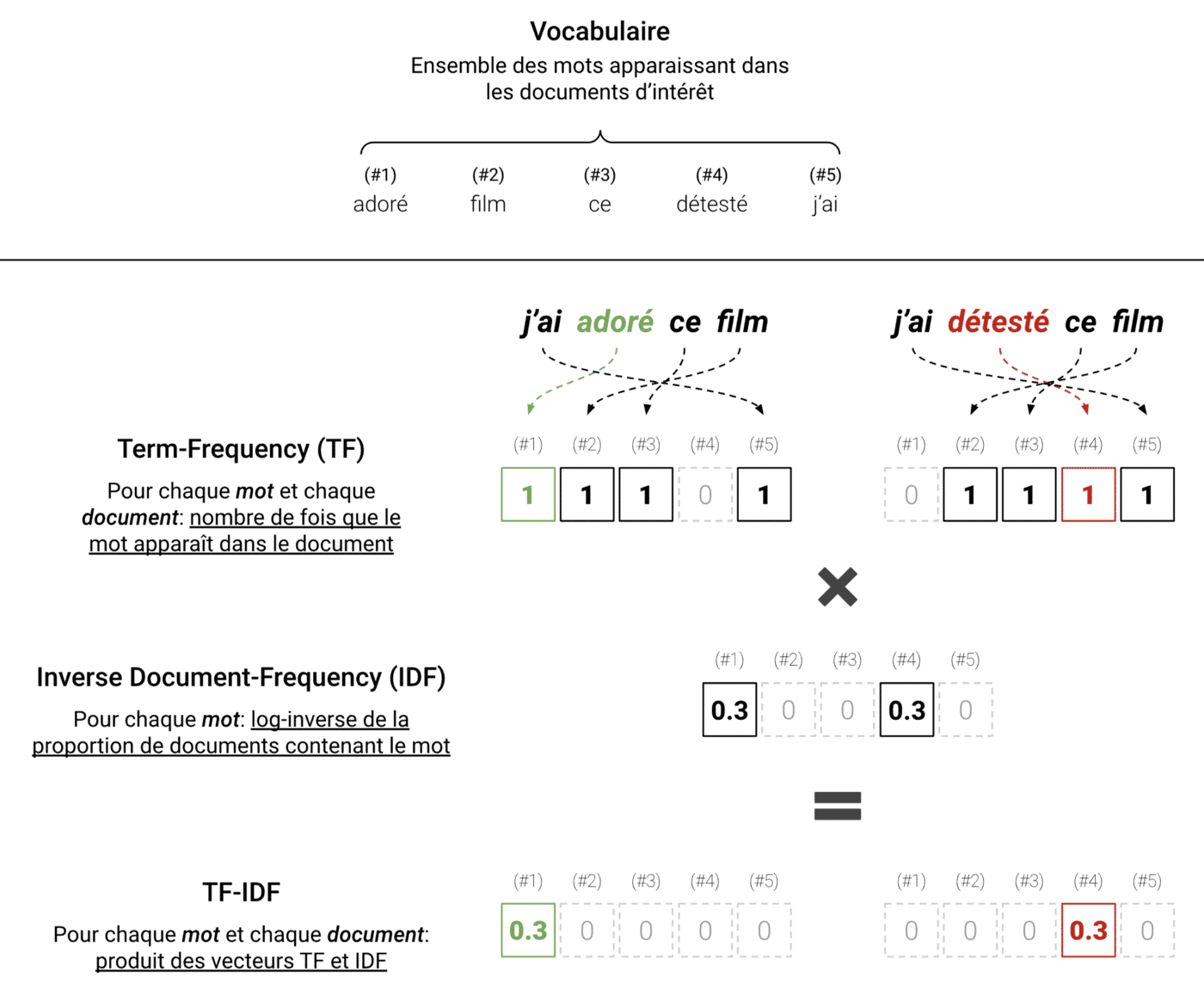
TF-IDF angewandt auf einen einfachen Fall mit zwei Sätzen. Hier sind die wichtigen Wörter „geliebt“ und „gehasst“. Wir sehen, dass TF-IDF die Texte repräsentiert, indem es das Rauschen herausfiltert und die relevanten Informationen beibehält.
In der Praxis ist die Anwendung von TF-IDF auf einen echten Datensatz sehr einfach. Dazu müssen Sie lediglich die Bibliothek scikit-learn verwenden, die verschiedene Werkzeuge für maschinelles Lernen in Python anbietet.
Natürliche Sprachverarbeitung ist ein interessantes, aber umfangreiches Thema. In diesem Artikel haben wir uns mit verschiedenen Aspekten der NLP vertraut gemacht und einen Standardfall der Textklassifizierung vorgestellt. Es gibt jedoch noch viel mehr zu erforschen.
In einem der nächsten Artikel werden wir die verschiedenen Parameter untersuchen, die angepasst werden können, um die TF-IDF-Methode an unterschiedliche Bedürfnisse anzupassen. Wir werden auch sehen, wie wir diese numerischen Darstellungen nutzen können, um ein Modell zu erstellen, das in der Lage ist, Entscheidungen zu treffen (d. h. unsere IMDb-Bewertungen automatisch zu kategorisieren). Abschließend werden wir einige fortgeschrittene Konzepte vorstellen, die es uns ermöglichen, weiter zu gehen und die neuesten Entwicklungen im Bereich der natürlichen Sprachverarbeitung zu verstehen.
Fazit
Die natürliche Spracherkennung und Verarbeitung verändert die Art, wie Menschen mit Computern kommunizieren. Sie ermöglicht es, Sprache zu verarbeiten, zu verstehen und in neue Kontexte zu übertragen.
In der Praxis setzen viele Unternehmen auf komplexe Verarbeitungspipelines, die aus mehreren spezialisierten Modulen bestehen. Diese sind jeweils auf bestimmte Teilaufgaben trainiert, etwa Klassifikation, Extraktion oder Strukturierung von Texten.
Ein Beispiel dafür ist die Lösung von DiliTrust, die große Mengen juristischer Dokumente analysiert. Das Unternehmen bietet eine fortschrittliche Contract Lifecycle Management (CLM)-Lösung an, die Funktionen wie OCR, Textklassifizierung und Entity Recognition umfasst, also genau jene Technologien, die moderne NLP-Anwendungen in der Praxis so wirkungsvoll machen.
Auf unserer Webseite finden Sie viele weitere Informationen und Ressourcen für die ersten Schritte.
Möchten Sie mit einem unserer Experten sprechen?