

DiliTrust sta sviluppando la propria intelligenza artificiale. Il team di Machine Learning (ML) lavora quotidianamente allo sviluppo di questo strumento unico.
La principale risorsa di lavoro del team ML è rappresentata dai contratti, poiché i modelli vengono addestrati per riconoscere automaticamente i dati contenuti in questi documenti.
In questo articolo, ti guideremo alla scoperta dell’Elaborazione del Linguaggio Naturale (NLP), un campo dell’intelligenza artificiale che consente l’analisi testuale e l’estrazione di informazioni rilevanti.
Cos’è l’NLP?
L’Elaborazione del Linguaggio Naturale (NLP) è un ramo dell’Intelligenza Artificiale (AI) con numerose applicazioni: dai traduttori automatici che comprendono e traducono testi in oltre cento lingue, agli assistenti virtuali che, combinati con tecnologie di Speech Processing, semplificano la gestione degli appuntamenti e l’organizzazione del calendario.
L’NLP è uno di quei campi che trasformano costantemente la nostra vita quotidiana.
Ma in cosa consiste esattamente?
In parole semplici, l’NLP si occupa di analizzare un testo ed estrarre informazioni rilevanti, alla base della creazione di sistemi capaci di svolgere un’ampia gamma di attività, dalle più semplici alle più complesse.
Esempi di applicazioni includono:
- Riconoscimento delle entità (es. individuazione automatica di nomi, date, importi, ecc.).
- Risposta automatica alle domande (es. risposta a domande su un evento citato in un documento).
- Classificazione testuale (es. categorizzazione automatica di un’e-mail come spam o non spam).
L’applicazione dell’NLP nel settore legale
L’uso della PNL su un singolo compito è spesso di interesse limitato, tranne che nei circoli accademici, dove l’attenzione si concentra sui meccanismi di funzionamento di questi metodi.
In pratica, le applicazioni più pratiche di NLP sfruttano al meglio queste tecnologie costruendo sistemi più complessi, o pipeline, che suddividono il problema in una successione di compiti semplici, ognuno dei quali viene poi affrontato utilizzando metodi di apprendimento automatico (ML) e regole per garantire la coerenza.
DiliTrust offre una soluzione semplificata per la gestione del ciclo di vita dei contratti (CLM) che comprende :
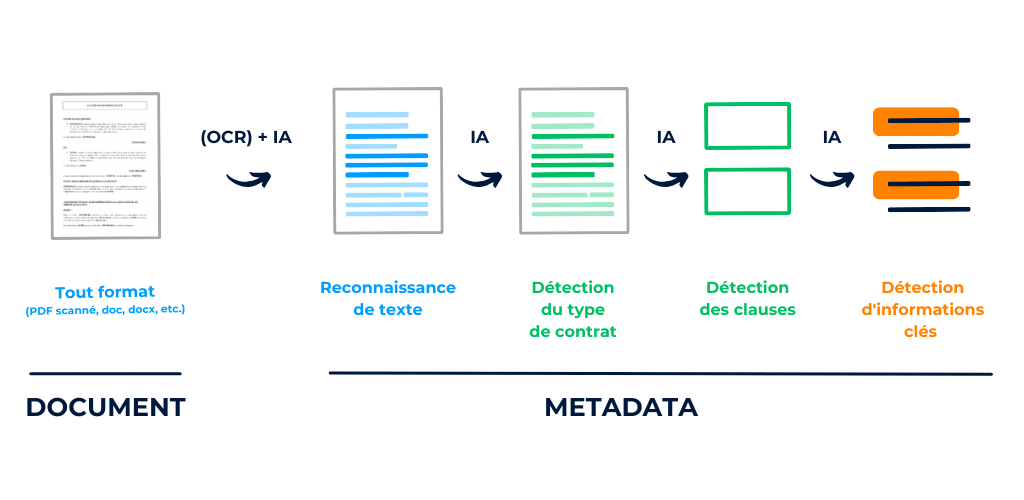
Illustrazione delle fasi principali della pipeline di analisi del contratto
Due fasi chiave nell’NLP: Rappresentazione e Decisione
Nonostante la varietà di compiti nell’NLP, due concetti fondamentali ricorrono quasi sempre:
- Rappresentazione (o vettorizzazione, embedding, ecc.):
Il testo, nella sua forma grezza, è incomprensibile per una macchina. Deve quindi essere trasformato in valori numerici utilizzabili per elaborazioni statistiche. - Decisione:
Sulla base delle rappresentazioni ottenute, vengono effettuati calcoli per prendere decisioni, come classificazione e estrazione di informazioni.
Per familiarizzare con questi concetti, analizzeremo un caso concreto di classificazione testuale, costruendo un sistema in grado di trasformare testi e classificarli in categorie di interesse.
Caso Studio: Analisi delle recensioni IMDb
Per comprendere meglio i metodi NLP, prendiamo in esame un caso pratico di classificazione testuale, focalizzandoci sul dataset IMDb, che contiene 50.000 recensioni di film pubblicate online.
L’obiettivo è determinare automaticamente se una recensione è positiva o negativa. Si tratta di un problema di classificazione binaria, poiché esistono solo due categorie.
Utilizzeremo il linguaggio di programmazione Python per costruire un modello di analisi del sentiment.
Fase 1: Download dei Dati
Prima di tutto, recupereremo il database di IMDb utilizzando lo strumento datasets fornito da HuggingFace :
Panoramica dei dati

Numero di documenti per categoria

Il dataset è composto da due parti, una dedicata all’addestramento del modello e l’altra al test.
All’interno di ciascuna parte, i commenti sono equamente suddivisi in categorie di interesse (0: negativo, 1: positivo).
Fase 2: Rappresentazione del Testo
Per costruire il nostro modello, dobbiamo trasformare i testi in rappresentazioni numeriche utili per gli algoritmi decisionali a valle.
Una trasformazione standard è il Term-Frequency Inverse Document-Frequency (TF-IDF), che riassume il contenuto di un testo basandosi sulla frequenza delle parole.
- Frequenza Term-Frequency (TF): conta il numero di occorrenze di ogni parola in un testo.
- Inverse Document-Frequency (IDF): diminuisce il peso delle parole più comuni per evidenziare quelle più significative.
Questa tecnica consente di filtrare il rumore e mantenere solo le informazioni rilevanti.
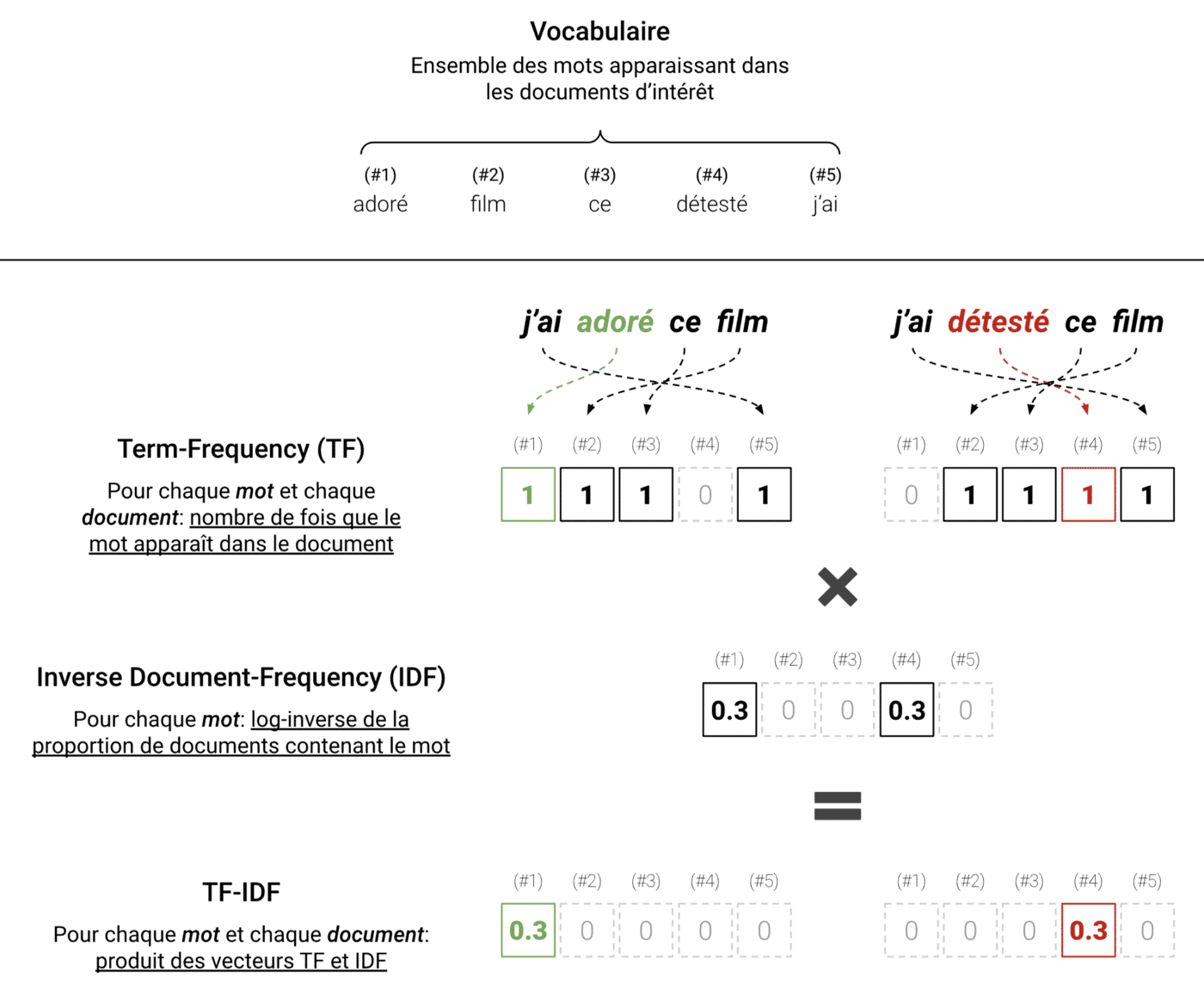
TF-IDF applicata in un caso semplice a due frasi. Qui le parole importanti sono “adorato” e “odiato”. Possiamo notare che TF-IDF rappresenta i testi filtrando il rumore e conservando le informazioni rilevanti.
Fase 3: Implementazione con Scikit-Learn
L’applicazione del metodo TF-IDF a un dataset reale è semplice grazie alla libreria Scikit-Learn, che offre strumenti di machine learning in Python.
Conclusioni e prossimi passi
L’elaborazione del linguaggio naturale è un campo affascinante e vasto. In questo articolo, abbiamo esplorato diversi aspetti dell’NLP e introdotto un caso di classificazione testuale.
Nel prossimo articolo, approfondiremo i parametri di ottimizzazione del TF-IDF per adattarlo a esigenze diverse. Inoltre, vedremo come utilizzare queste rappresentazioni numeriche per costruire un modello in grado di prendere decisioni, come la classificazione automatica delle recensioni IMDb.
Infine, introdurremo alcuni concetti avanzati per comprendere gli sviluppi più recenti nell’NLP.



